
Protocolo (8 bits)
El campo de protocolo permite a la Capa de red pasar los datos al protocolo apropiado de la capa superior.
Los valores de ejemplo son: 01 ICMP; 06 TCP; 17 UDP
Tipo de servicio (8 bits)
Se usa para determinar la prioridad de cada paquete.
Este valor permite aplicar un mecanismo de Calidad del Servicio (QoS) a paquetes de alta prioridad, como aquellos que llevan datos de voz en telefonía.
Desplazamiento de fragmentos(13 bits)
Identifica el orden en el cual ubicar el fragmento del paquete en la reconstrucción.
Señalizador de Más fragmentos (1 bit)
es un único bit en el campo del señalizador usado con el Desplazamiento de fragmentos para la fragmentación y reconstrucción de paquetes.
Cuando un host receptor ve un paquete que llega con MF = 1, analiza el Desplazamiento de fragmentos para ver dónde ha de colocar este fragmento en el paquete reconstruido.
Cuando un host receptor recibe una trama con el MF = 0 y un valor diferente a cero en el desplazamiento de fragmentos, coloca ese fragmento como la última parte del paquete reconstruido.
Un paquete no fragmentado tiene toda la información de fragmentación cero (MF = 0, desplazamiento de fragmentos = 0).
Señalizador de No Fragmentar (1 bit)
Si se establece el bit del señalizador No Fragmentar, entonces la fragmentación de este paquete NO está permitida.
Encabezado de Paquete IP V4

Version (4 bits)
Contiene el número IP de la versión(4).
Longitud del encabezado (IHL)(4 bits)
Especifica el tamaño del encabezado del paquete.
Longitud del Paquete(16 bits)
Este campo muestra el tamaño completo del paquete, incluyendo el encabezado y los datos, en bytes.
Identificacion (16 bits)
Este campo es principalmente utilizad para identificar úncamente fragmentos de un paquete IP original.
Checksum del encabezado (16 bits)
El campo de checksum se utiliza para controlar errores del encabezado del paquete.
Opciones (variable length)
Existen medidas para campos adicionales en el encabezado IPv4 para proveer otros servicios pero éstos son rara vez utilizados.
Otros Campos IPv4 del encabezado

A medida que crece el número de hosts de la red, se requiere más planificación para administrar y direccionar la red.
En lugar de tener todos los hosts conectados en cualquier parte a una vasta red global, es más práctico y manejable agrupar los hosts en redes específicas.
Estas redes más pequeñas generalmente se llaman subredes.
Las redes pueden agruparse basadas en factores que incluyen:
ubicación geográfica,
propósito, y
propiedad.
Redes – Separación de Hosts en grupos comunes

Agrupación de hosts de manera geográfica
El agrupamiento de hosts en la misma ubicación, como cada construcción en un campo o cada piso de un edificio de niveles múltiples, en redes separadas puede mejorar la administración y operación de la red.
Ubicación Geográfica

Agrupación de hosts para propósitos específicos.
Los usuarios que tienen tareas similares usan generalmente software común, herramientas comunes y tienen patrones de tráfico común.
A menudo podemos reducir el tráfico requerido por el uso de software y herramientas específicos, ubicando estos recursos de soporte en la red con los usuarios.
Propósito

Agrupación de hosts para propiedad
Utilizar una base organizacional (compañía, departamento) para crear redes ayuda a controlar el acceso a los dispositivos y datos como también a la administración de las redes.
Propiedad

Los problemas comunes con las redes grandes son:
Degradación de rendimiento
Temas de seguridad
Administración de direcciones
¿Porqué separar hosts en redes?

Grandes cantidades de hosts conectados a una sola red pueden producir volúmenes de tráfico de datos que pueden extender, sin saturar, los recursos de red como la capacidad de ancho de banda y enrutamiento.
La división de grandes redes reduce el tráfico a través de las internetworks.
Las comunicaciones de datos reales entre los hosts, la administración de la red y el tráfico de control (sobrecarga) también aumentan con la cantidad de hosts. Los factores que contribuyen de manera significativa con esta sobrecarga pueden ser los broadcasts de red.
Un broadcast es un mensaje desde un host hacia todos los otros hosts en la red.
Un host inicia un broadcast cuando se requiere información sobre otro host desconocido.
Grandes cantidades de hosts generan grandes cantidades de broadcasts que consumen el ancho de banda de la red.
Los broadcasts son una herramienta necesaria y útil usada por protocolos para permitir la comunicación de datos en redes.
A una red también se la conoce como un dominio de broadcast.
Por qué dividir hosts en redes? – Rendimiento

La red basada en IP, que luego se convirtió en Internet.
La división de redes basada en la propiedad significa que el acceso a los recursos externos de cada red y desde estos pueden estar prohibidos, permitidos o monitoreados.
Por ejemplo, la red de una universidad puede dividirse en subredes para la administración, investigación y los estudiantes.
Dividir una red basada en el acceso a usuarios es un medio para asegurar las comunicaciones y los datos del acceso no autorizado, ya sea por usuarios dentro de la organización o fuera de ella.
La seguridad entre redes se implementa en un dispositivo intermediario (router o firewall) en el perímetro de la red.
La función del firewall que realiza este dispositivo permite que sólo datos conocidos y confiables accedan a la red.
Por qué dividir hosts en redes? – Seguridad

Internet está compuesta por millones de hosts, y cada uno está identificado por su dirección única de capa de red (IP).
Esperar que cada host conozca la dirección de cada uno de los otros hosts sería sobrecargar gravemente su rendimiento.
Dividir grandes redes para que estén agrupados los hosts que necesitan comunicarse, reduce la sobrecarga de conocer todas las direcciones.
Los hosts sólo necesitan conocer la dirección de un dispositivo intermediario al que envían paquetes para todas las otras direcciones de destino.
Este dispositivo intermediario se denomina gateway.
El gateway es un router en una red que sirve como una salida desde esa red.
Por qué dividir hosts en redes? – Administración de direcciones.

La dirección IPv4 lógica de 32 bits .
Se dividen en cuatro grupos de ocho bits (octetos).
Cada octeto es convertido a decimal.
4 valores decimales separados por punto (período). Por ejemplo – 192.168.18.57
La dirección IPv4 es jerarquica y esta compuesta por 2 partes.
La primera parte identifica la red a la que pertenece y la segunda parte identifica un host en la red.
En el ejemplo, los primeros 3 octetos, (192.168.18), pueden identificar la parte de red de la dirección, y el ultimo octeto, (57) identifica al host.
Esto se llama direccionamiento jerarquico porque la parte de red indica la red en la que cada dirección host única está ubicada.
Los routers sólo necesitan conocer cómo llegar a cada red en lugar de conocer la ubicación de cada host individual.
División de Redes – Redes a partir de redes.

Al número de bits de una dirección utilizada como la porción de red se llama longitud del prefijo (máscara de subred).
Por ejemplo, si una red utiliza 24 bits para expresar la parte de red de una dirección se dice el prefijo es / 24.
En los dispositivos de una red IPv4, un número separado de 32 bits llamado máscara de subred indica el prefijo.
La extensión de la duración de prefijo o máscara de subred permite la creación de estas subredes.
División de Redes – Redes a partir de redes.

Cuando un host necesita comunicarse con otra red, un dispositivo intermediario, o router, actúa como un gateway hacia la otra red.
Para comunicarse con un dispositivo en otra red, un host usa la dirección de este gateway, o gateway predeterminado, para reenviar un paquete fuera de la red local.
Esta dirección de gateway es la dirección de una interfaz del router que está conectado a la misma red que el host.
El router también necesita una ruta que defina dónde reenviar luego el paquete. A esto se le llama dirección del siguiente salto.
Si el router cuenta con una ruta disponible, el router reenviará el paquete al router del siguiente salto que ofrezca una ruta hacia la red de destino.
Como respaldar la comunicación fuera de nuestra red.

La función de la capa de red es transferir datos desde el host que origina los datos hacia el host que los usa.
Si el host destino esta en la misma red,
El paquete se envía entre 2 hosts en el medio local sin necesitar un router.
Si el host de destino y el host de origen no están en la misma red,
La red local envía el paquete desde el origen a su router de gateway .
El router examina la porción de la red de la dirección de destino del paquete y envía el paquete a la interfaz adecuada.
Si la red de destino está conectada directamente a este router, el paquete se reenvía directamente a ese host.
Si la red de destino no está conectada directamente, el paquete es enviado a un segundo router, que es el router del siguiente salto.
El paquete que se reenvía pasa a ser responsabilidad de este segundo router.
Muchos routers o saltos a lo largo del camino pueden procesar el paquete antes de llegar al destino.
Paquetes IP- Como llevar datos de extremo a extremo.

1
2

3
4

5
6

El gateway, que también se conoce como gateway predeterminado, es necesario para enviar un paquete fuera de la red local.
Este gateway es una interfaz del router conectada a la red local.
La interfaz del gateway tiene una dirección IP que concuerda con la dirección de red de los hosts.
Los hosts están configurados para reconocer la dirección como gateway.
Gateway Default o predeterminado
El gateway predeterminado se configura en un host.
En una computadora con Windows, se usan las herramientas de las Propiedades del Protocolo de Internet (TCP/IP) para ingresar la dirección IPv4 del gateway por defecto.
Gateway – La salida de nuestra Red.

Confirmando la Puerta de Enlace (Gateway) y la ruta.
Comandos ipconfig o route print en la linea de comandos en una computadora con Windows.
El comando route tambien se usa en Linux or UNIX.
Gateway – La salida de nuestra Red.
route print

Este proceso de reenvío es denominado enrutamiento.
Para reenviar un paquete a una red de destino, el router requiere una ruta hacia esa red.
Si no existe una ruta a una red de destino, el paquete no puede reenviarse.
La ruta hacia esa red sólo indicaría el router del siguiente salto al cual el paquete debe reenviarse, no el router final.
Si el paquete se origina en un host o se reenvía por un dispositivo intermediario, el dispositivo debe tener una ruta para identificar dónde enviar el paquete. Un router toma una decisión de reenvío para cada paquete que llega a la interfaz del gateway.

La tabla de enrutamiento almacena información sobre redes conectadas y remotas.
Las redes estan directamente conectadas a una de las interfaces del router.
Cuando se configura una interfaz de router con una dirección IP y una máscara de subred, la interfaz se vuelve parte de esa red.
Las redes remotas son redes que no están conectadas directamente al router.
El administrador de red puede configurar manualmente las rutas a estas redes en el router o bien pueden obtenerse automáticamente a través de protocolos de enrutamiento.
Ruta- El camino hacia una red.

Los routers en una tabla de enrutamiento tienen tres características principales:
Red de destino
Siguiente salto
Métrica
El router hace coincidir la dirección de destino del encabezado del paquete con la red de destino de una ruta en la tabla de enrutamiento y reenvía el paquete al router del siguiente salto que especifica dicha ruta.
Si hay dos o más rutas posibles hacia el mismo destino, se utiliza la métrica para decidir qué ruta aparece en la tabla de enrutamiento.
El router también puede usar una ruta predeterminada para reenviar el paquete.
La ruta predeterminada se usa cuando la ruta de destino no está representada por ninguna otra ruta en la tabla de enrutamiento.
Ruta- El camino hacia una red.
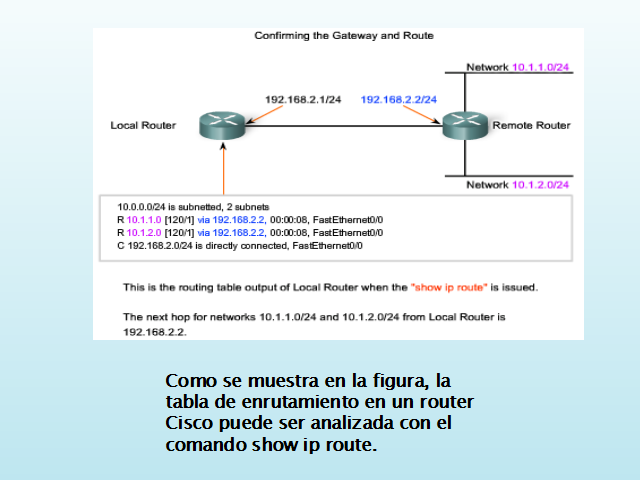
Como se muestra en la figura, la tabla de enrutamiento en un router Cisco puede ser analizada con el comando show ip route.

Los hosts también requieren una tabla de enrutamiento para asegurarse de que los paquetes de la capa de red estén dirigidos a la red de destino correcta. Un host crea las rutas que se utilizan para reenviar los paquetes que origina.
A diferencia de la tabla de enrutamiento en un router, que contiene tanto rutas locales como remotas, la tabla local del host comúnmente contiene su conexión o conexiones directa(s) a la red y su propia ruta por defecto al gateway.
La tabla de enrutamiento de un host de computadora puede ser analizada en la línea de comandos con los comandos netstat -r, route o route PRINT.
Se pueden utilizar las siguientes opciones para el comando route para modificar el contenido de la tabla de enrutamiento:
route ADD
route DELETE
route CHANGE
Ruta- Tabla de enrutamiento del host.

netstat -r, or route PRINT will produce the same output
Ruta- Tabla de enrutamiento del host.

La red de destino que aparece en la entrada de la tabla de enrutamiento, llamada ruta, representa un rango de direcciones host y, algunas veces, un rango de direcciones de red y host.
Como se muestra en la figura, si un paquete llega a un router con una dirección de destino de 10.1.1.55, el router reenvía el paquete al router del siguiente salto asociado con una ruta a la red 10.1.1.0.
Si una ruta a 10.1.1.0 no está enumerada en el enrutamiento, pero está disponible una ruta a 10.1.0.0, el paquete se reenvía al router del siguiente salto para esa red.
Entonces, la prioridad de la selección de una ruta para el paquete que va a 10.1.1.55 sería:
1. 10.1.1.0
2. 10.1.0.0
3. 10.0.0.0
4. 0.0.0.0 (ruta predeterminada si estuviera configurada)
5. Descartada
Entradas de la Tabla de Enrutamiento.

Un router puede configurarse para que tenga una ruta predeterminada.
Una ruta predeterminada es una ruta que coincida con todas las redes de destino.
En redes IPv4 se usa la dirección 0.0.0.0 para este propósito.
La ruta predeterminada se usa para enviar paquetes para los que no hay entrada en la tabla de enrutamiento para la red de destino.
Los paquetes con una dirección de red de destino que no combinan con una ruta más específica en la tabla de enrutamiento se reenvían al router del siguiente salto asociado con la ruta predeterminada.
Ruta Predeterminada

Un siguiente salto es la dirección del dispositivo que procesará luego el paquete.
Para un host en una red, la dirección de gateway predeterminado (interfaz del router) es el siguiente salto para todos los paquetes destinados a otra red..
En la tabla de enrutamiento de un router, cada ruta enumera un siguiente salto para cada dirección de destino que abarca la ruta.
Las redes conectadas directamente a un router no tienen dirección del siguiente salto porque no existe un dispositivo de Capa 3 entre el router y esa red.
Algunas rutas pueden tener múltiples siguientes saltos.
Esto indica que existen múltiples pasos hacia la misma red de destino.
Éstas son rutas alternativas que el router puede utilizar para reenviar paquetes.
Siguiente Salto- A donde se envía luego el paquete.

El enrutamiento se hace paquete por paquete y salto por salto.
Cada paquete es tratado de manera independiente en cada router a lo largo de la ruta.
En cada salto, el router examina la dirección IP de destino para cada paquete y luego verifica la tabla de enrutamiento para reenviar la información.
El router hará una de tres cosas con el paquete:
Reenviarlo al router del siguiente salto
Reenviarlo al host de destino
Descartarlo
Envio de Paquetes – Traslado del paquete hacia su destino.


Como se muestra en la figura, si la tabla de enrutamiento no contiene una entrada de ruta más específica para un paquete que llega, el paquete se reenvía a la interfaz que indica la ruta predeterminada, si la hubiere.
La ruta predeterminada se conoce también como gateway de último recurso.
Este proceso puede producirse varias veces hasta que el paquete llega a su red de destino.
Las rutas predeterminadas son importantes porque el router del gateway no siempre tiene una ruta a cada red posible en Internet.
Si el paquete es reenviado usando una ruta predeterminada, eventualmente llegará a un router que tiene una ruta específica a la red de destino.
Envio de Paquetes- Uso de la ruta predeterminada

A medida que el paquete pasa a través de saltos en la internetwork, todos los routers necesitan una ruta para reenviar un paquete.
Si, en cualquier router, no se encuentra una ruta para la red de destino en la tabla de enrutamiento y no existe una ruta predeterminada, ese paquete se descarta.
IP no tiene previsto devolver el paquete al router anterior si un router particular no tiene dónde enviar el paquete.
Se utilizan otros protocolos para informar tales errores.
Envío de Paquetes – Traslado del paquete hacia su destino

La tabla de enrutamiento contiene información que un router usa en sus decisiones al reenviar paquetes.
Esta información de ruta puede configurarse manualmente en el router o aprenderse dinámicamente a partir de otros routers en la misma internetwork.
Para las decisiones de enrutamiento, la tabla de enrutamiento necesita representar el estado más preciso de rutas de red a las que el router puede acceder.
La información de enrutamiento desactualizada significa que los paquetes no pueden reenviarse al siguiente salto más adecuado, lo que causa demoras o pérdidas de paquetes.
Protocolos de enrutamiento – Como compartir rutas.

Las rutas a redes remotas con los siguientes saltos asociados se pueden configurar manualmente en el router. Esto se conoce como enrutamiento estático. Una ruta predeterminada también puede configurarse estáticamente.
Si el router está conectado a otros routers, se requiere conocimiento de la estructura de internetworking.
Debido a que los paquetes se reenvían en cada salto, cada router debe estar configurado con rutas estáticas hacia los siguientes saltos que reflejan su ubicación en la internetwork.
Si no se realiza la actualización periódica, la información de enrutamiento puede ser incompleta e inadecuada, lo que causa demoras y posibles pérdidas de paquetes.
Enrutamiento Estático

No siempre es factible mantener la tabla de enrutamiento por configuración estática manual. Por eso, se utilizan los protocolos de enrutamiento dinámico.
Los protocolos de enrutamiento son un conjunto de reglas por las que los routers comparten dinámicamente su información de enrutamiento.
Como los routers advierten los cambios en las redes para las que actúan como gateway, o los cambios en enlaces entre routers, esta información pasa a otros routers..
Cuando un router recibe información sobre rutas nuevas o modificadas, actualiza su propia tabla de enrutamiento y, a su vez, pasa la información a otros routers.
Los protocolos de enrutamiento comunes se incluyen:
Protocolo de información de enrutamiento (RIP)
Protocolo de enrutamiento de gateway interno mejorado (EIGRP)
Open Shortest Path First (OSPF)
Enrutamiento Dinámico

Aunque los protocolos de enrutamiento proporcionan routers con tablas de enrutamiento actualizadas, existen costos.
Primero, el intercambio de la información de la ruta agrega una sobrecarga que consume el ancho de banda de la red.
Segundo, la información de la ruta que recibe un router es procesada extensamente por protocolos como EIGRP y OSPF para hacer las entradas a las tablas de enrutamiento.
Los routers que emplean estos protocolos deben tener suficiente capacidad de procesamiento como para implementar los algoritmos del protocolo para realizar el enrutamiento oportuno del paquete y enviarlo.
El enrutamiento estático no produce sobrecarga en la red ni ubica entradas directamente en la tabla de enrutamiento.
El costo para un enrutamiento estático es administrativo, la configuración manual y el mantenimiento de la tabla de enrutamiento aseguran un enrutamiento eficiente y efectivo.
 Página anterior Página anterior | Volver al principio del trabajo | Página siguiente  |